WildCat Classifier Training and Application
The WildCat weakly supervised learning algorithm is used for tangle (and other object) detection and burden mapping on whole-slide histology images. This document describes how to train and apply WildCat.
PICSL Histology Annotation Server (PHAS) is used to place training samples.
We assume your PHAS server is accessible at
https://my.histoannot.url
A Linux machine or VM with an NVidia GPU is required for training
Jupyter notebooks are used to train and validate classifiers
Patch download and organization
Overview
Training should be performed by creating a project on the PICSL Histology Annotation Server (PHAS), defining a task and a labelset, and placing boxes around inclusions of interest.
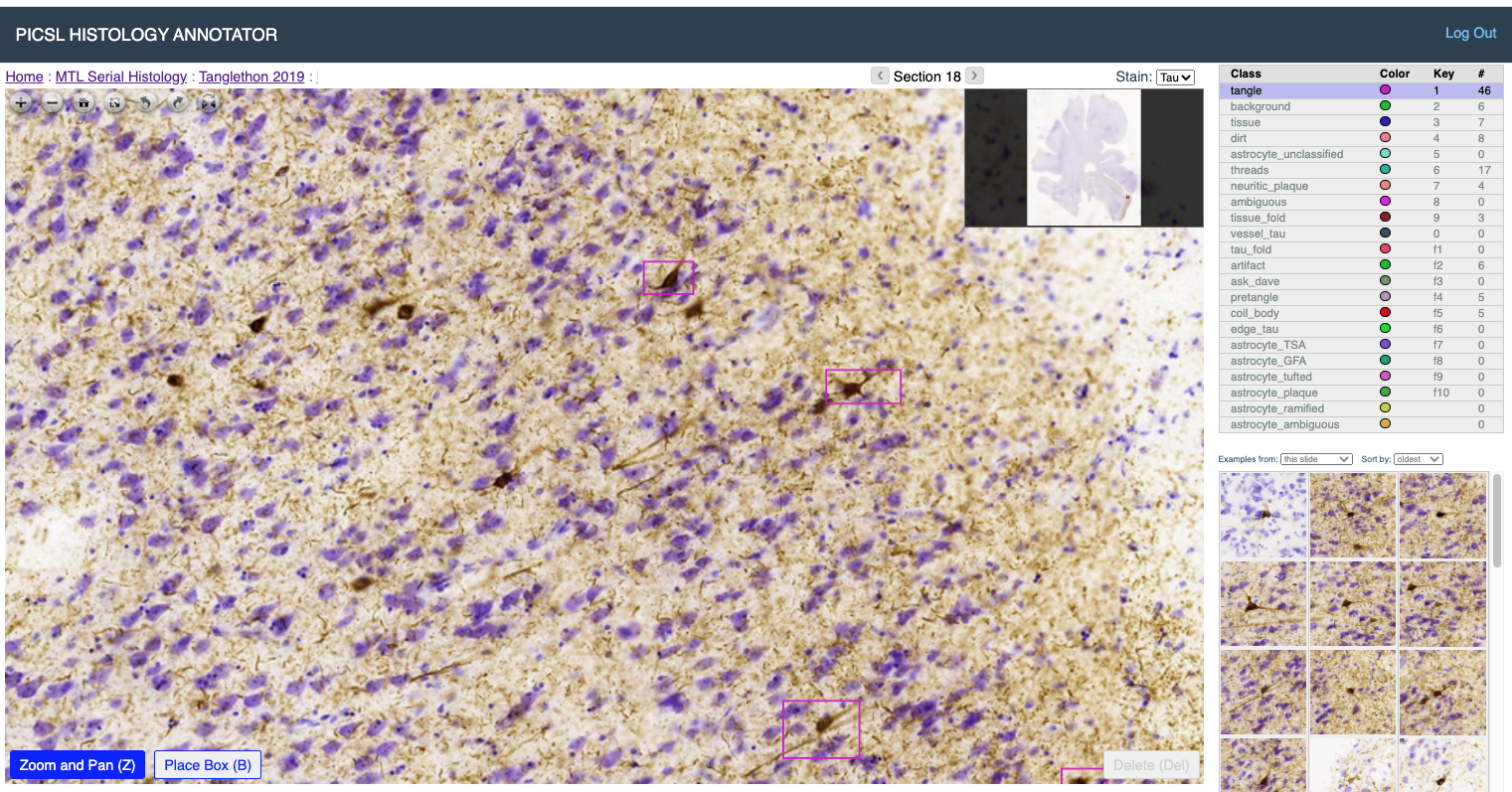
Download patches
Clone the repository https://github.com/pyushkevich/tanglethon-ipynb.
Create a root directory for patch download. Here we refer to it as
$PATCH_ROOTThe script
scripts/clone_samplesis used to download samples from PHAS:clone_samples: download training samples from a histoannot server usage: clone_samples.sh [options] options: -s <url> Server URL (default: https://histo.itksnap.org) -k <file> Path to JSON file with your API key -t <int> Task ID on the server -o <dir> Output directory for the samples
Obtain a key from your PHAS server by navigating to URL
https://my.histoannot.url/auth/api/generate_keyand save in a.jsonfile. Here we assume you store it in~/.histoannot_key.json. Note that when you navigate to this URL your earlier keys are invalidated.Determine which task to get patches from. On PHAS, the task id is a number that is included in the URL when you select a task. Here we let
$TIDrefer to the task id.Clone the samples into the directory
$PATCH_ROOTclone_samples.sh -s https://my.histoannot.url -k ~/.histoannot_key.json -t $TID -o $PATCH_ROOT/patches
Verify patch organization. You should see a collection of files like these:
$PATCH_ROOT/patches/all_patches/23409.png $PATCH_ROOT/patches/all_patches/23410.png ...
Create a WildCat experiment
A training task involves classifying a set of foreground objects vs. a set of background objects. For example, tangle-like objects vs. non-tangles. Both foreground and background can include more than one class from PHAS training.
The script
scripts/organize_foldsis used to organize samples from PHAS into PyTorch-compatible datasets.organize_folds: generate train/val/test folds for samples from histoannot usage: organize_folds.sh [options] required options: -w <dir> Working directory (created by clone_samples) -e <string> Experiment id/name (folder created in working directory) -l <file> JSON file describing the classes and how they map to labels optional: -n <int> Maximum number of samples to include (per fold) -t <int> Max number of samples per class to take for train (2000) -v <int> Max number of samples per class to take for val (1000) -T <int> Max number of samples per class to take for test (0, i.e., all) -R <int> Random seed -s <file> File listing specimens ids to use for testing. These specimens will not be included in trainingDetermine the set of available labels in your training set. Navigate to (replace
[proj_id]with actual project ID).https://my.histoannot.url/dtrain/[proj_id]/labelsets
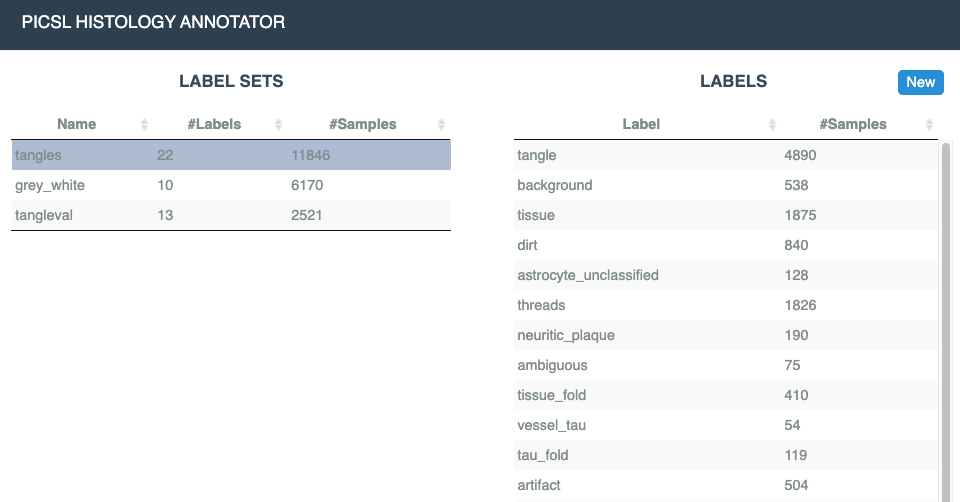
Create a
.jsonfile (e.g.,$PATCH_ROOT/exp01.json) for your experiment. This file explains how classes on the PHAS server are organized to form foreground/background classes, and which classes on PHAS are ignored. Note the regular expression".*"is used to select all PHAS classes that have not been matched to either tangle or ignore categories. The order in which categories are specified matters here.[ { "classname": "tangle", "labels": [ "GM_tangle", "GM_pretangle" ], "ignore": 0 }, { "classname": "ignore", "labels": [ "ask_expert", "ambiguous" ], "ignore": 1 }, { "classname": "nontangle", "labels": [ ".*" ], "ignore": 0 } ]If you wish to split your specimens into train/test, create a text file
$PATCH_ROOT/exp01_test.txtlisting specimens to be used for testing. You will notice thatclone_samples.shcreated a specimen listingspecimens.txtit its output directory.Run the organizing script:
organize_folds.sh -w $PATCH_ROOT/patches -e exp01 -l $PATCH_ROOT/exp01.json -s $PATCH_ROOT/exp01_test.txt
When completed you should have the following directory structure containing symlinks to patch
.pngfiles:$PATCH_ROOT/patches/exp01/patches/<train|val|test>/<tangle|nontangle>/12345.png
Train WildCat classifier in Jupyter
Alternatively, you can train the classifier from the command line, see below
Start the Jupyter notebook app
Duplicate, edit and run the notebook
generic-wcu-train.ipynb.At the beginning of the “Model Setup” section, change
exp_dirto point to your experiment data directory ($PATCH_ROOT/patches/exp01)You can also change some model training parameters here
Run all cells in the notebook. This should train the classifier for 30 epochs and save the model and parameters to the files
$PATCH_ROOT/exp01/models/wildcat_upsample.dat $PATCH_ROOT/exp01/models/config.json
You should expect to have about 95% validation accuracy during traning. Could be lower or higher, of course depending on the type of inclusion being analyzed.
Evaluate WildCat classifier on test patches
This step is optional but nice to evaluate classifier accuracy and look at the kinds of patches the classifier is failing on.
In Jupyter, shutdown all kernels to clear NVidia GPU memory
Duplicate, edit and run the notebook
generic-wcu-examine.ipynb.At the beginning of the “Validation Setup” section, change
exp_dirto point to your experiment data directory ($PATCH_ROOT/patches/exp01)Also set the
cname_objandcname_bkgto your object/non-object classes (e.g., “tangle”/”non-tangle”)Run all the cells in the notebook
This will generate the confusion matrix and ROC plot
It will visualize examples of false positives and false negatives on the test set
You will also see sample heat maps generated by WildCat for sample inputs
Evaluate WildCat classifier on whole-slide image
This step is also optional and will take longer. It allows you to explore whole-slide heat maps.
In Jupyter, shutdown all kernels to clear NVidia GPU memory
Download a whole-slide image that you wish to analyze (we will refer to it as
$WSI_DIR/test_wsi.tiff).File must be in pyramidal format readable by OpenSlide, see WSI Processing
Duplicate, edit and run the notebook
generic-wcu-scanslide.ipynb.At the beginning of the “Experiment Setup” section, change
exp_dirto point to your experiment data directory ($PATCH_ROOT/patches/exp01)In the same cell, change
wsi_fileto point to the whole-slide image$WSI_DIR/test_wsi.tiffRun the sections of the notebook:
In the “Load WSI”, the slide will be loaded
In the “Generate burden map” section, the slide will be analyzed patch by patch, generating burden map
In the “Visualize burden map” section, different parts of the slide can be plotted with the burden map. You will need to specify the regions of interest for zoomed in burden maps.
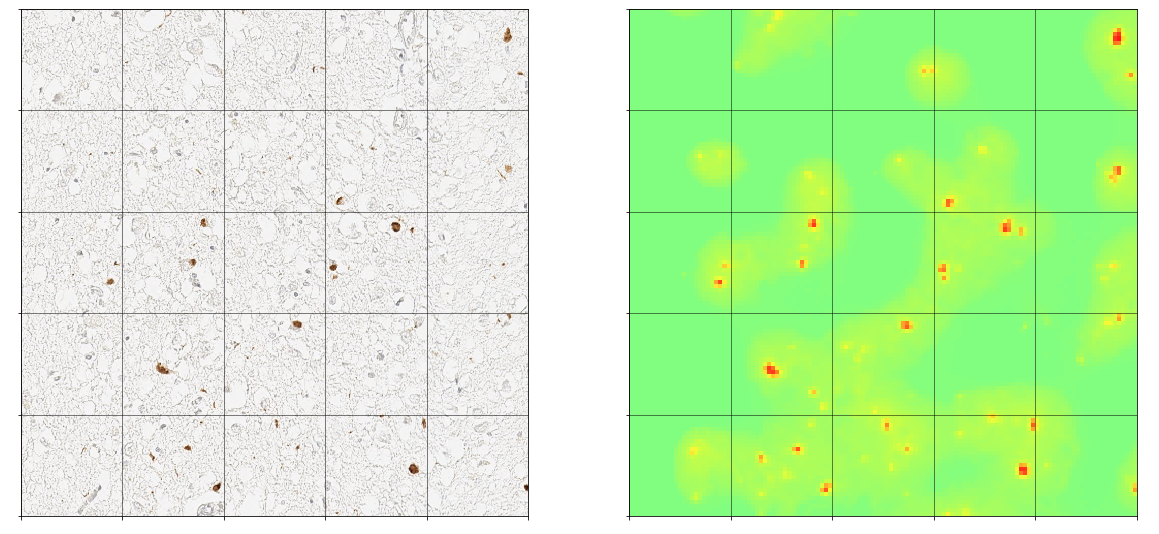
Validate WildCat classifier vs. Manual Ratings and Object Counts
Follow these instructions if you would like to compare the quantitative burden measure to manual counts of objects of interest (e.g., tangle counts), and subjective ratings. In the histology annotation platform, set up a new task, as shown below. Large boxes are used to designate areas for validation. They can be assigned labels corresponding to ratings. Small boxes are used to mark all individual inclusions of each type that are being counted.
When you are ready to perform the evaluation:
Clone the samples into the directory
$PATCH_ROOT. SetCTIDto the counting task id. Note the -X flag, which will download patches in the size drawn as opposed to default 512x512 patches previously cloned.clone_samples.sh -s https://my.histoannot.url -k ~/.histoannot_key.json -t $CTID -o $PATCH_ROOT/counting -X
Duplicate, edit and run the notebook
generic-wcu-counts.ipynb.You will need to set
exp_dirto the directory where you performed WildCat training, andcnt_dirto$PATCH_ROOT/counting. You will also need to set the dictionariescontainer_labelsandobjects_of_interest_labelsto match the labels used to mark large boxes and individual inclusions that should be included in the counting. Towards the end of the notebook, you will need to setbox_labelsto indicate your rating categories for the large boxes.
Training WildCat network from the command line
Clone the repo https://github.com/pyushkevich/tangle-cnn-prod
Install required packages
pip -r requirements.txt
Run training script as follows
# Run this to see all options for training python wildcat_main.py train --help # Run this to run with the default options python wildcat_main.py train \ --expdir $PATCH_ROOT/patches/exp01The script will create a directory
$PATCH_ROOT/patches/exp01/modelscontaining your trained classifier
Applying WildCat models in batch mode
Clone the repo https://github.com/pyushkevich/tangle-cnn-prod
Prepare your WSI files for reading by OpenSlide, see WSI Processing
Run the following script:
# Run the code python -u scan_tangles.py apply \ --slide $wsi_file \ --output wsi_burden.nii.gz \ --network $path_to_model